I recently had the opportunity to change the password hashing algorithm we used in one of our services. In this post, we briefly compare the older SHA-256 algorithm with a more modern implementation that is Argon2id. I will shed some light on some statistics you can use to make the right choice of parameters for the Argon2 algorithm with respect to memory cost and compute cost. I have also shared the code snippet I used to carry out my research spike.
Drawbacks of SHA-256 and why Argon2
Up until recently, our legacy service made use of the SHA-256 password hashing algorithm. Some points to consider:
- Among the different attributes of a password hashing function, one important attribute is that it should be sloooow. It should be computationally expensive to impede password cracking operations and thus make the life of an adversary more difficult. The SHA-256 algorithm can calculate a hash of about 140 MB per second which is not necessarily slow. To give you context, if your password policy allowed only lowercase, uppercase english alphabets and the digits from 0 to 9, with a max length of 7 characters, it would take just about 4 days for a single threaded operation to try all the possibilities in the UTF-8 character set!
$$timeInSeconds = {{{(26 + 26 + 10) ^ 7} * (2 * 7)} \over {140 * 10 ^ 6}}$$ $$timeInDays = {timeInSeconds \over {60 * 60 * 24}} \sim 4$$
- The rise of bitcoin mining has led to the availability of cheap specialized hardware with GPU / FPGA / ASIC which can perform computations at much faster rate than our regular CPUs. This has made it possible to generate hashes that can be used by lookup tables.
After discussions with the security team, we decided to use the Argon2i algorithm to generate hashes. It is AES based which is implemented by most modern x64 and ARM processors in their instruction set extensions leveling the playing field between an attacker’s hardware and our non-specialized CPUs. The algorithm provides us with knobs to balance the tradeoff between how easily a hash is calculated and the amount of compute / memory needed to produce it (security and user experience).
Tastes better with salt
The reason why we use salts while hashing passwords is so that they randomize the hash that is generated for the same input value. So if two users have the same password, their hashes will still be different. This will further slow down the process of cracking the password by an adversary.
In my opinion, there are a couple of drawbacks in the existing systems in terms of how we use and store salts.
- We just store them in the database along with user passwords. So if an adversary has access to the database table, he has access to the salt. The only additional hurdle he faces is that he has to still calculate the new hash value.
- Sometimes people use a common salt for all the passwords that are generated. This in my opinion does not add any additional security measure. If the adversary is able to find that out, he has the password hash of all the users who have the same password by calculating it just once.
The use of Argon2 solves 2 problems with respect to salts -
It internally generates a new salt for each new request to generate a hash. So if you request a hash for the same plaintext multiple times, each time you are going to get a different hash. Since the salt is handled internally, we don’t have to store the unique salts associated with each user in our database.
Statistics on Argon2 Parameters and tuning Argon2
Argon2 uses the following input parameters while calculating a hash -
- Salt length
- Hash length
- Parallelism
- Memory cost
- Iterations
I carried out a research spike to come up with parameters that could help us have a balance between the difficulty involved in coming up with a password hash and the time taken to do it.
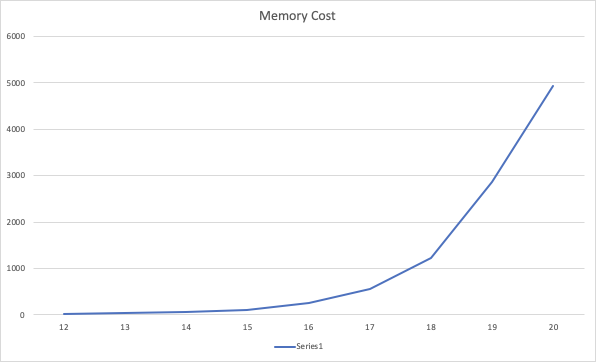
Memory Cost
If you observe, the memory cost shoots up when the power increases from 1 « 17 and upwards.
Iterations
There is an exponential increase in the compute required when your parameter value is increased from 1 « 7 and upwards

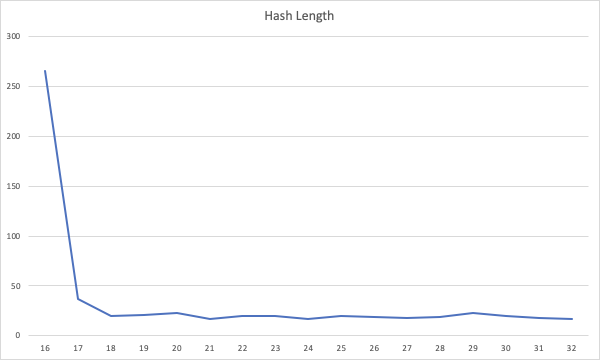
HashLength
The hash length that is generated by the algorithm has no bearing on the amount of time needed to calculate it. What is even more intriguing is that there is a one time fixed cost when we try to generate the hash the first time which probably accounts for the big first value in the below graph.
Code Snippet
Last but not the least, I am also attaching the code snippet I wrote up to run the above tests. It is written in Scala
Note - you need the following dependencies
compile group: 'org.springframework.security', name: 'spring-security-crypto', version: '5.2.0.RELEASE'
compile group: 'org.bouncycastle', name: 'bcprov-jdk15on', version: '1.64'